Täysin uutta liiketoimintafunktiota perustettaessa mielessä on paljon kysymyksiä. Mihin se sijoittuu organisaatiorakenteessa. Kenen pitäisi johtaa sitä, ja kenelle hän raportoi. Mitä investointeja täytyy tehdä? Hajautettu vai keskitetty? Ostetaanko ulkopuolista osaamista, kuinka paljon, ja mihin tarkoitukseen?
Tässä kolmiosaisessa blogisarjassa käsittelen kolmesta eri näkökulmasta, mitä kaikkea data science praktiikkaa perustavan organisaation täytyy huomioida. Tämä osa käsittelee investointeja. Kannattaako ennakoiva analytiikka hankkia pakettiohjelmistona vai räätälöitynä? Onko jatkuva kehitys parempi malli kuin projektit? Mitä pohjatöitä täytyy tehdä, ennen kuin ennakoivaan analytiikkaan voidaan päästä?
Sarjan muut osat:
Osa 1: Organisaatio ja operatiivinen malli
Osa 2: Osaaminen ja rekrytointi
Projekteja vai jatkuvaa kehitystä?
IT-alalle on harmillisesti vakiintunut tapa tehdä kehitystyö aina projekteina. Kaikki työ ei kuitenkaan taivu luontevasti projektimalliin, jossa työn tekemisellä on selkeä alku, loppu, ja toimituksen laajuus. Tieteellisestä menetelmästä ammentava data science -prosessi on yksi tällainen:

Yksinkertaistettu data science -prosessi
Työ lähtee käyntiin liiketoimintakokemukseen perustuvan hypoteesin muodostamisesta. Mitkä asiat voisivat selittää ilmiötä, jota pyritään ennustamaan? Voisiko sen, minkä tuotteen verkkokauppa-asiakas seuraavaksi ostaa, ennustaa hänen aikaisemmasta ostohistoriastaan ja siitä, millä sivuilla hän on tämän session aikana käynyt? Vaikuttaako ostopäätökseen, tuleeko hän sivustolle hakukoneesta, sähköpostista vai sosiaalisesta mediasta? Entä käytettävä päätelaite tai maantieteellinen sijainti?
Mikäli hypoteesin testaamiseen tarvittavaa dataa ei ole jo saatavilla, se täytyy kerätä. Kerätystä datasta laitetaan syrjään osa testausta varten, ja lopun pohjalta rakennetaan ennustava malli. Mallin toimivuus testataan sivuun laitetulla datalla. Mikäli malli ei suoriudu ennustamisesta riittävän hyvin, kaikkia ilmiötä selittäviä muuttujia ei todennäköisesti olla vielä löydetty, ja hypoteesia pitää muuttaa.
Työn iteratiivisen luonteen takia on vaikea sanoa, kuinka monta yritystä tarvitaan hyväksyttävään ennustustarkkuuteen, tai onko sitä edes mahdollista saavuttaa saatavilla olevalla datalla. Siksi kiinteän toimituksen projektit eivät sovellu ennakoivan analytiikan kehittämiseen.
Paljon mielekkäämpää on suunnata tietty vuosittainen budjetti ennakoivalle analytiikalle, ja tehdä priorisoidulta listalta töitä budjetin puitteissa. Kunkin tehtävän voi aina tietysti aikarajoittaa, ja jos näyttää siltä, että tietyn ajan sisällä ei tapahdu riittävästi edistystä, voidaan tehdä päätös kyseisen tehtävän parkkeeraamisesta tai hylkäämisestä. Kaikki hankkeet eivät tule onnistumaan. Tärkeintä on kokeilla ideoita rohkeasti kiintymättä niihin liikaa.
Pakettisoftaa vai räätälöityä koodia?
Ennakoivan analytiikan ratkaisut jakautuvat periaatteessa kolmeen arkkityyppiin: pakettiohjelmistot, graafiset työkalut ja täysin räätälöidyt ohjelmistot.
Pakettiohjelmistot
Pakettiohjelmistojen arvolupaus on yleensä ”anna mitä tahansa dataa tästä asiasta ja teen siitä optimaalisen ennustuksen”. Tämän lupauksen yksinkertaisuus on houkutteleva, mutta toisaalta niin sanottu ”feature engineering” eli ennusteessa käytettävien attribuuttien muodostaminen ja valinta on tunnetusti yksi tärkeimpiä työvaiheita hyvin toimivan ennustavan mallin rakentamisessa. Mikäli et onnistu kaappaamaan kaikkia ennustettavaa ilmiötä selittäviä attribuutteja, ennustus ei voi toimia.
Hyvällä datalla ruokitut pakettiohjelmistot suoriutuvat tehtävästään usein ”ihan hyvin”, mutta jos haluat puristaa viimeisetkin prosentit ennustuksen tarkkuudesta irti, pakettiohjelmisto ei välttämättä ole hyvä valinta.
Lisäksi pakettiohjelmistojen yksi kiusallinen piirre on se, että pahin kilpailijasi voi ostaa saman ohjelmiston, ja heille todennäköisesti myös yritetään myydä sitä. Jos yrität saada investoinnilla kilpailuetua tai olla edelläkävijä, tämä ei ole paras vaihtoehto.
Graafiset työkalut
Tätä kategoriaa edustavat tuotteet kuten IBM SPSS Modeler, SAS Enterprise Miner ja RapidMiner. Näillä työkaluilla kehitetään analyyttisiä työnkulkuja, joissa voidaan yhdistää dataa eri lähteistä, muuntaa se sopivaan muotoon, rakentaa ennustavia malleja, ja soveltaa malleja uuteen dataan. Työkalu toteuttaa useimmat tunnetut algoritmit, joista analyytikko voi valita ongelmaan parhaiten soveltuvan.
Näiden etu verrattuna pakettiohjelmistoihin on, että ennustustarkkuudesta saa välitöntä palautetta jo mallia rakennettaessa. Tämä antaa osviittaa siitä, onko kaikki ennustettavaa ilmiötä selittävä data saatu kerättyä, vai pitääkö alkuperäistä hypoteesia korjata ja kerätä lisää dataa, tai johtaa olemassa olevasta datasta uusia muuttujia. Lisäksi ennustava malli kehitetään ja optimoidaan aina tapauskohtaisesti, siinä missä pakettiohjelmiston on pakko olla melko yleisluontoinen soveltuakseen mahdollisimman monelle asiakkaalle.
Räätälöidyt ohjelmistot
Mikäli yleisimmät algoritmit eivät syystä tai toisesta sovellu ongelmaasi, tarvitaan täysin räätälöity ratkaisu. Esimerkiksi elokuvan IMDB-arvosanan ennustaminen sen trailerin perusteella vaatii jo hieman luovuutta. Yleisestikin erityisesti rakenteettoman datan – tekstin, kuvien, videon ja äänen – analysointi on usein luontevinta tehdä itse kirjoitetulla ohjelmalla.
Tällä hetkellä rikkaimmat ohjelmistokirjastot tilastotieteeseen, ennustavaan analytiikkaan ja koneoppimiseen löytyvät R ja Python ohjelmointikielille, jonka takia ne ovat saavuttaneet suosionsa. Lähtökohtaisesti kaiken minkä voi tehdä graafisilla työkaluilla voi myös kirjoittaa jommallakummalla kielellä. On tapauskohtaista kumpaa lähestymistapaa kannattaa käyttää.
Pohjatyöt
Data scienceen ei välttämättä ole mielekästä tai edes mahdollista hypätä suoraan, ellei tiettyjä pohjatöitä ole tehty. Itse miellän tämän nelivaiheisena prosessina:
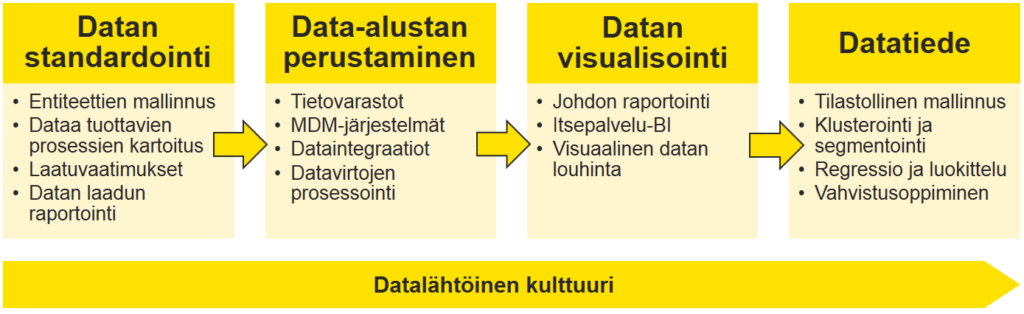 Vaiheet datatieteeseen
Vaiheet datatieteeseen
Datan standardointi
Jotta eri liiketoimintaprosesseissa ja eri järjestelmissä syntyvää dataa voidaan hyödyntää, sen täytyy olla yhdenmuotoista ja hyvälaatuista. Liiketoiminnan kannalta keskeisimmät entiteetit kuten esimerkiksi ”asiakas” ja ”tuote” täytyy mallintaa, niitä tuottavat ja kuluttavat prosessit ja järjestelmät täytyy kartoittaa, ja niille täytyy määrittää laatukriteerit – pakolliset kentät ja datan formaatti. Kaksoiskappaleet täytyy siivota pois, ja sama tietue täytyy olla tunnistettavissa eri järjestelmien yli yksiselitteisesti.
Datan mallinnus helpottaa muun muassa tietovarastojen suunnittelua. Dataa tuottavien prosessien tunnistaminen auttaa estämään tulevia laatuongelmia, ja datan laadun mittaaminen ja raportointi korjaavine toimenpiteineen on esiehtona sille, että dataan voi edes luottaa. Garbage in, garbage out pitää paikkansa data sciencen kohdalla erityisen hyvin.
Suuri osa datatieteilijän työajasta menee datan siivoamiseen ja muokkaamiseen, jonka takia laadukkaaseen dataan kannattaa panostaa.
Data-alustan perustaminen
Tietovarasto on käytännössä jokaisen analytiikka-alustan tärkein kulmakivi. Tarpeen mukaan tietovarastoteknologiaksi voidaan valita perinteinen relaatiokanta, suuremmille tietomäärille MPP-tyylinen tietokanta, ja äärimmäisissä tapauksissa jokin Hadoop-pohjainen ratkaisu kuten Hive.
Joskus nähdään myös NoSQL-toteutuksia kuten dokumenttivarasto MongoDB:n tai key-value store DynamoDB:n päälle rakennettuja tietovarastoja. Tietovarastot ovat kuitenkin lähtökohtaisesti luonteeltaan relationaalisia, ja ei-relationaalisen tietokannan valitseminen saattaa aiheuttaa ongelmia datan eheydessä, koska viiteavainrajoitteita ei valvota tietokannan toimesta.
Ennen kuin sukellat Hadoopin maailmaan, kannattaa pitää mielessä, että kyseinen teknologia on alun perin suunniteltu koko WWW:n indeksin tallentamiseen. Tuletko oikeasti käsittelemään niin paljon dataa, vai riittäisikö esimerkiksi Redshift, BigQuery tai Snowflake, tai ihan perinteinen relaatiokanta? Yhden tai muutaman palvelimen Hadoop-ympäristö on ratkaisu ongelmaan jota ei ole. Toki vaikkapa suuri määrä kuvia tai videoita saattaa helpostikin vaatia Hadoopin tavoin skaalautuvaa alustaa, mutta jos data mahtuu yhdelle palvelimelle, Hadoop ei pääse oikeuksiinsa.
Viimeisen viiden vuoden aikana päätään on nostanut uusi tiedonkäsittelyn paradigma tietovirtalaskenta (stream computing), jossa ideana on tunnistaa poikkeuksia tai muuten kiinnostavia tapahtumia jatkuvasta tietovirrasta ja reagoida näihin. Virran dataa ei lähtökohtaisesti ole tarkoituskaan tallentaa. Näyte ”normaalista” tilasta riittää, jotta poikkeamat voidaan tunnistaa. Tämä lähestymistapa voi sopia erityisen hyvin sensoridatan analysointiin, josta valtaosa saattaa olla toisteista ja merkityksetöntä. Miksi tallentaa joka ikinen sensorilukema tietovarastoon, jos ne pääsääntöisesti ovat epäkiinnostavia? Toinen tyypillinen käyttötapaus stream computingille on valvontakameroiden videosyötteen analysointi. Kaiken videokuvan tallentaminen vie paljon tilaa. Paljon tehokkaampaa on tunnistaa ja tallentaa poikkeustilanteet, ja reagoida niihin.
Datan visualisointi
Ihminen on äärimmäisen huono ymmärtämään numeroita, mutta erittäin hyvä tulkitsemaan visuaalisesti asioiden välisiä suhteita ja trendejä. Jo pelkästään se, että datasta kiinnostuneet voivat saada helposti siihen pääsyn, ja että heillä on hyvät työkalut sen visualisoinniksi, voi viedä organisaation päätöksentekoa valovuosia datalähtöisemmäksi. Esimerkiksi Tableaun tai vastaavan itsepalvelu-BI-työkalun käyttö ei vaadi Excelin kanssa sinut olevalta henkilöltä merkittäviä ponnisteluja. Datan käyttäminen oletuksien testaamiseen ja kysymyksiin vastaamiseen on aina varmempi vaihtoehto kuin parhaiten tienaavan henkilön mielipide.
Datan näkyväksi tekeminen ja sitä kautta organisaation päätöksenteon kulttuurin ohjaaminen datalähtöisemmäksi valmistaa seuraavaan loogiseen askeleeseen, data scienceen.
Datatiede
Seuraava vaihe matkalla kohti datalähtöistä päätöksentekoa onkin varsinainen datatiede. Organisaation data on tässä vaiheessa jo yhdenmuotoista, laadukasta ja luotettavaa, ja data science -tiimillä alkaa olla edellytykset aloittaa työnsä.
Tuotteen menekkiä ennustetaan tilastoista, hapantunut demografiapohjainen asiakassegmentointi voidaan vaihtaa todelliseen käyttäytymiseen perustuviin klustereihin, ensi kvarttaalin myyntiä aletaan ennustaa regressiomalleilla, ja palveluntarjoajan vaihdolle alttiit asiakkaat tunnistetaan CRM-datasta binääriluokittelijalla.
Asko Relas (kirjoittaja työskenteli Loihde Advancella joulukuuhun 2018).